异步编程
这个总结先回顾了一个通常的I/O操作怎么导致当前线程blocking, 借此回顾了一下操作系统调度的一些概念; 然后以web应用这个I/O密集型任务的例子, 按照发展顺序引出了异步编程; 总结一个异步编程库要实现什么; 然后简单介绍了一下libuv的源代码和工作机理; 讲道理本来是要讲node.js从callback编程paradigm(event-based programming paradigm)发展到现在Promise-based async programming十分流行, 应该要介绍一下Promise的思想、如何实现, 可以这一部分还没写; 最后又提了一嘴gevent, 以及分析介绍了一下gevent 的monkey patch对C库不管用, 所以有一些极度平台的patch dynamic libC I/O wrap function call的方法。
async VS. sync. 底层底层底层
异步(async)编程是一种相对于同步编程的方式(应该这么说嘛 = =), 在类似web应用这种I/O密集型程序中十分重要, 这是为什么呢? 先详细的回顾一下, 在Linux上用高级语言Python用同步编程做socket试图recv的例子, 会发生什么:
- 比如用Python 2.7.10编程时候, 从一个socket里读数据:
data = soc.recv(1024). 会调用sock_recv_guts函数, 里面调用了libC提供的socket API:nread = recv(s->sock_fd, read_buf, segment, flags);. 这个C函数定义在Modules/socketmodule.c里, 这个文件是用Python-C API写的模块。Python标准库里的socket模块是对该C模块的一个简单封装。 - 已经从高级语言到libC了, 下一步要做的事情就是libC的recv里调用系统调用了. 调用系统调用
recvfrom陷入内核态. - 这个线程陷入内核态之后,
recvfromsystem call从file descriptor拿到file结构体从而拿到对应的socket结构体, 会调用到socket->ops->recvmsg, 其中这个socket结构体的ops字段就是一个operation函数指针集合(这是Linux内核下层不同的协议/设备对上层实现统一API常用的技巧). 这个socket结构体是BSD socket, 是提供给上层用户用的一个简单的socket结构体, 几种不同的类型和这些类型对应的ops写在这里. 如果用户创建socket的时候指定SOCK_STREAM类型, 也就是BSD tcp socket, 调用socket->ops->recvmsg即调用inet_recvmsg会调用sock->sk_prot->recvmsg函数, 注意这里的sock结构体已经是AF socket, 是一个给内核用的信息更多的套接字表示. 内核对套接字两个表示, socket和sock互相存有对方的指针方便reference. 现在这个sock的sk_prot又是一个operation函数指针集合, 这个sock结构会在inet_create里初始化, 其中sk->sk_prot初始化为之前的inet_protosw里的protofield, 可以看到之前的不同BSD socket类型注册表里给出了TCP sock的sk_prot为tcp_protoperation集合, 我们感兴趣的recvmsg字段是tcp_recvmsg: socket驱动(在这里TCP/IP协议栈其实是built in在OS里的)发现该socket还没有数据可以读, 于是会把该线程的PCB(process controlling block)被加入该I/O设备(也就是驱动维护的一个数据结构的)的waiting_queue(一个双向列表)中。net/core/sock.c:sk_wait_data函数会initialize一个wait_queue_t类型的struct:DEFINE_WAIT_FUNC(wait, woken_wake_function);, 这个struct记录了:current: 马上要block的线程的PCB(x86 linux下task_struct)func:woken_wake_function为在有event时唤醒这个这个线程要调用的函数, 大多数设备驱动的实现(包括这里)是default_wait_function. 这个wake up线程的函数做的事情很简单:- 设置PCB的state为
TASK_RUNNING, 注意linux里TASK_RUNNINGstate代表正在运行或者可运行, 不仅仅代表正在运行。 - 如果该进程优先级足够高, 可能尝试直接context switching.
- 设置PCB的state为
- 当OS(或者驱动)完成了把线程信息加入到某个设备的waiting queue之后, 这个线程就block住了, 操作系统会从维护的可运行的线程的数据结构里调度其它可以运行的线程运行.
- after some time… 当硬件(这里是网卡)收到了消息, 会raise IRQ线, 驱动的IRQ handler会被调用, 驱动会调用之前提到的
wait_queue_t.funcwake up在自己的waiting_queue的里的线程. 然后这个线程变成可运行状态(TASK_RUNNING), 可能就能在之后被操作系统调度运行. - 被调度执行了: 切换回该线程的context后, 把数据读出来放到socket buffer里, 由于user space的
ubuf已经用import_single_range函数利用iov机制和一个msghdr连接起来了,tcp_recvmsg函数读数据时就会通过层层包装但是最后还是调用copy_to_iter其实底层就是memcpy把从socket读到的数据(从套接字读的数据先在sk_buffsocket buffer结构体里存着)拷贝到iov_iter保存的ubuf位置. 然后用户应用程序的libc:recv调用就结束啦~
可以看到, 一旦一个线程做了某个阻塞式的I/O(blocking I/O), OS会负责挂起该线程, 让其它线程占有CPU运行。如果我们做Web应用, 只用单个线程:
- 单线程: 每个时候只能serve一个用户, 每次accept之后先跟这个用户通信完了再看能不能accept下一个TCP连接。那么在大多数时间里, 这个线程都是block在I/O操作上, 没有在CPU上运行的, 这不能忍。一个最简单的想法是, 多线程或者多进程嘛, 这样可以同时serve的用户可能能多些.
- 多进程/多线程: fork/create on requests: 不少web服务器采取的是这种工作方式。例子: 可以查看Python标准库里的
SocketServer.py里的ForkingMixin和ThreadingMixin, 分别是在accept一个新连接之后fork一个子进程或者创建一个线程负责与一个client通信。 - 但是每个新连接来了都要fork/create一个新进程/线程, 处理完之后又销毁, 这样的开销太大, 所以有一些web服务器采用的是pre-fork工作模式: 一般是:
- 一堆pre-fork的worker进程都从listening socket尝试accept, 建立连接之后blocking的只serve一个client, 调用上层应用的API(Python里是一个遵循WSGI interface标准的上层应用);
- 一个master进程负责监视worker进程, worker挂了要重启啊, 或者根据用户信号增减worker这样的工作。
通常这样的解决方案已经不错了, 比如我用Flask写一个web应用, 跑很多gunicorn, 然后前端加一个负载均衡器, 即使用
SyncWorker的模式也还工作的不错。但是如果你的web服务器需要继续scale up, 你可能希望在gunicorn里也使用async worker. gunicorn里提供的async worker:GeventWorker基于Python里的异步编程库gevent实现, 看看下一条~ 以及最后一章还会讨论一些gevent的事情. - 我们还想要更大的concurrency! 同时可以serve 很多个用户, 不过基本serve这些用户的工作大多数都是在等待I/O. 为了不让线程无意义的block在I/O上, 我们要用异步编程(async programming): 所有I/O操作都不再block, 而是在user space程序发现你这个I/O任务需要等, 我不愿意陷入内核态, 任操作系统摆布给我挂起, 比如我accept了一个client建立连接socket1后, 这个client socket1不给我发东西, 我还想先再serve下一个client呢。所以在用户态把socket1放在一个要等待的fd列表里. 然后我们不管这个client了, 返回! 又把控制权交给eventloop, 而eventloop会发现有人把一个新的socket1放在了要等待的列表里, eventloop的实现会调用类似
epoll_ctl的调用把这个socket1加入epoll监视事件的fd列表。然后eventloop负责把你这个socket1和其它所有曾经在这个线程里要等待I/O event的fd一起调用epoll_wait, 如果在某个fd上有事件发生, 就相应调用该fd对应的callback(所以在把socket1放入等待队列时记得同时放入一个对应的callback)。listening的socket当然也是被这个epoll所管理的, 所以如果在client socket1发来东西之前有另一个用户试图连接, 那么我们就会先serve该用户, 而不是傻等client socket1发来东西再考虑别人是不是需要处理啊。
上面提到的epoll系列的调用是Linux操作系统提供的notification subsystem, 具体操作系统是怎么实现的, 原理上并不难理解。我们可以看到有了这个notification subsystem的帮助, 其实eventloop的实现相当于把OS实现的多线程调度显式放到了用户空间, 但是省去了context switching, 调度单元变得更小。在OS发现I/O中断发生时会调用callback: default_wake_function这种把线程状态设置为可运行, 之后线程什么时候再被调度回CPU, 做context switching然后运行就是操作系统的事情了; 而在这里当eventloop发现有一些I/O event(由OS提供的机制告知的)会调用这些I/O event相应注册的callback, callback调用完全就是一个函数调用操作嘛, 不像操作系统中需要切换线程, 涉及到开销较大的context switching操作。
OK, 上面的介绍完了之后, 我们大概知道:
- 操作系统对普通的blocking I/O操作的处理机制
- async编程是什么
- 对于类似web服务这样的I/O密集型任务, 比起依靠操作系统的多线程, 为什么用async编程方法实现更好。以及一个简单的发展的过程
所以: 支持异步编程的底层框架要做的两件重要的事情:
- 要实现一个event loop利用操作系统提供的notification subsystem监听/分发事件. 能够让开发人员进行event-based programming
- 原来是blocking的I/O系统调用, 基本都要封装(wrap)/补丁(patch)成了non-blocking的, 改成只是向用户态运行的event loop注册一个需要监听的fd和相应的callback。
还有一点是可选的: 上面第一点第二句提到了eventloop对上层提供了event-based programming的API, 而event-based(callback-based) programming其实是需要程序员改变自己的编程套路, 把常用的同步编程paradigm改成基于callback的。一些异步编程库/语言runtime会在eventloop上进一步封装(比如gevent, golang runtime), 实现轻量级的user space context switching, 在user space中做轻量级调度(借用gevent的术语, 我们称这个调度单元为一个greenlet; 也有不少的地方称此调度单元为coroutine)。通过这种对程序员几乎透明的context switching的实现异步I/O, 可以保持用户编程时候paradigm仍然是同步编程。相信和上面操作系统在I/O发生时对线程的调度行为的类比发现, 这种异步编程库做的事情更类似在user space做了OS做的事情, 此时往eventloop中注册的callback也是类似操作系统内部做线程调度时设置的default_wake_function: 一般做的事情就是设置该greenlet可运行或者直接context switch回那个greenlet。当然和操作系统的调度也有不同, 下面是一个简单的比较:
| 操作系统 | user space scheduler | |
|---|---|---|
| preemptive scheduling | 抢占式调度, 即使线程没有I/O操作, 但是一个时间片跑完之后, OS还是会把你踢下去调度别人 | 大多数实现是合作式调度, 当一个greenlet调用了一个patch过的I/O函数的时候会yield自己的执行权. 此时由scheduler调度其它可执行的greenlet执行 |
| context switching | OS负责, 开销大 | user space程序负责, 通过一些换栈指针的trick实现, 开销小. 调度单元greenlet里只包括pc, 少量的栈空间数据, 一些必要的寄存器数据等 |
关于这个preemtpive scheduling有必要再说两句, 为什么操作系统要用抢占式调度算法, 这是因为操作系统上跑的是不同用户的不同程序, 也可能有比较恶意的程序, 要是在操作系统上也实现合作式调度, 某些程序根本不会让出自己的执行权。而相反, 我在用异步编程写程序时, 程序基本都是我写的或者一些我自己调用的库, 当然我是知道这个程序是I/O密集, 每个greenlet都会或多或少在一些节点主动让出执行权。我不会愚蠢到写一个程序一直在死循环计算x = x + 1这种一直占着cpu不放的greenlet的。
下面给出我比较熟悉的异步编程库, 或语言本身就支持异步编程的runtime的例子:
- gevent: 提供同步编程接口; N-to-1的user-space合作式调度; N个greenlets跑在一个OS线程里, 有一个hub greenlet负责运行eventloop和在队列里选择下一个要调度执行的greenlet。由于gevent开发时, Python类似socket这些标准库已经大行其道, 所以gevent做了一个monkey-patch, 把这些Python标准库里的blocking I/O调用都patch成了non-blocking的。
- golang: 提供同步编程接口; 最新版本实现的是user-space N-to-M的半抢占式合作式调度; 从Go 1.2之后为了address上面说到的还是有一些一直死循环计算的goroutine 一共m个, 当
m >= GOMAXPROCS的时候其它的goroutine就没办法得到执行权, 所以Go 1.2加入了在function entry调用scheduler的机制, 使得如果你的死循环goroutine里调用了runtime提供的非inline的函数时, 可以部分模拟抢占式调度, 但是并不是操作系统的基于timer interrupt的抢占式调度。毕竟还是认为cooperative调度对于大多数应用都是足够的。 - node.js: 提供的是基于callback的编程接口; eventloop和wrapped/patched blocking I/O call基于libuv
不管是对上层提供callback event-based programming接口(node.js)还是对上层提供同步编程接口(gevent, golang)的异步库, 它们的共同点是都需要一个eventloop的实现, 以及要提供怎么向eventloop注册事件的函数, 方便这些库patch原来的blocking系统调用。下面我们以node.js基于的libuv库为例, 分析一个eventloop的典型实现。
libuv
下面所有讲到某个API的实现的时候,都是用的libuv 399b08aa9f02362a14f8d2975ac7f70b91bb0963版本的针对LINUX的代码做为例子, 虽然给的名字是
uv_<>但是给的链接和讨论的细节都是在unix/目录下linux的实现, 函数名也会是加了一个下划线的:uv__<>
event loop
libuv作为一个异步编程库,当然要实现一个Eventloop, Eventloop的实现是platform-specific的, 要看操作系统提供什么系统调用。libuv当然要负责把不同操作系统(甚至包括windows)的细节抹盖掉。eventloop提供的接口如下: <!–
-
- 初始化该event loop的task queue
- 初始化epoll instance eg. Linux:
epoll_create1 - 初始化event loop的锁等
- 初始化async_watcher(callback为
uv__aysnc_io)和signal_watcher, 其中会创建epoll监听的pipe:uv__async_start里 - 将这个新创建的event loop加入全局的
uv__loops记录 –>
uv_run: 运行eventloop的入口, eventloop运行的时候会做什么可以见下面的uv_io_init: 初始化io handle, 包括设置file descriptor和callback等信息uv_io_start: 向eventloop注册此io handle:QUEUE_INSERT_TAIL(&loop->watcher_queue, &w->watcher_queue);加入loop的watcher_queue(这是一个双向列表); 并且把放到一个从fd到handle的map表loop->watchers里.- 还有一些
uv_idle_init/start,uv_prepare_init/start之类的… 就不赘述了.
event loop的cycle如下图所示:
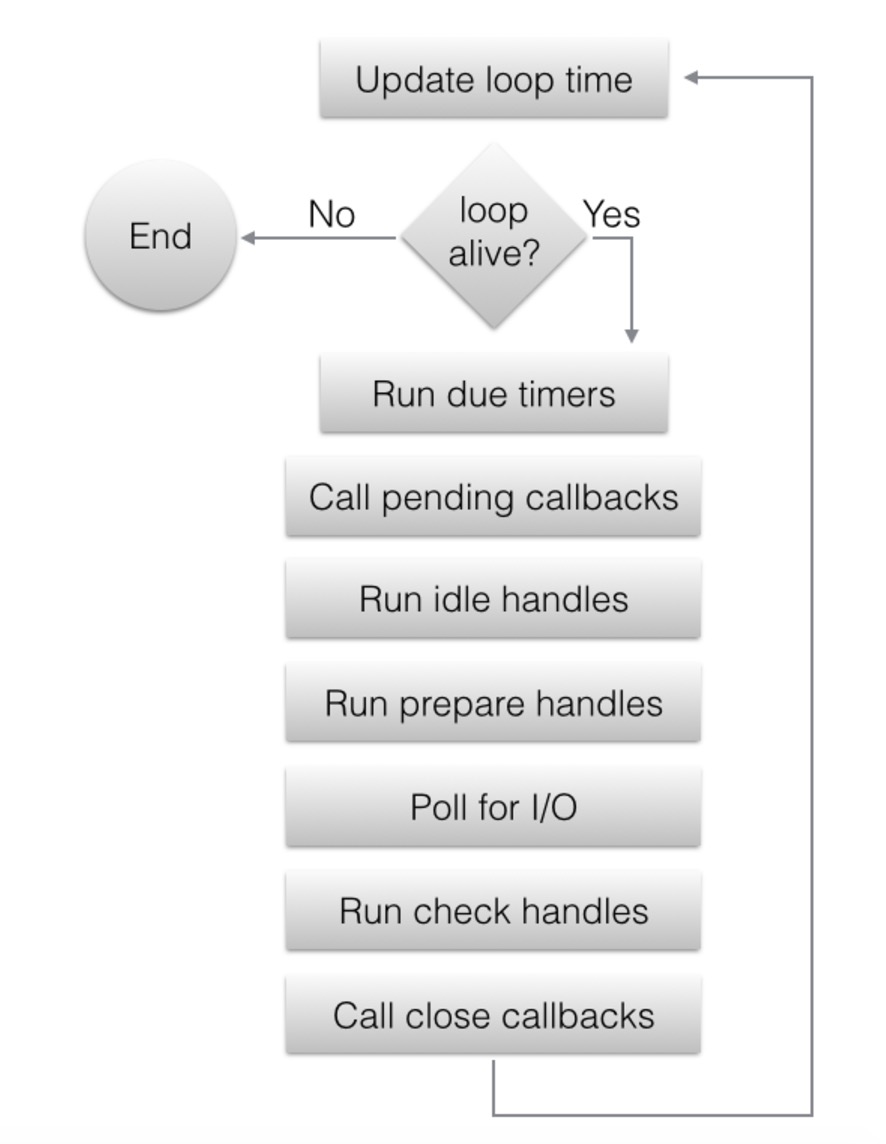
上面这些接口是一个底层的和eventloop交互的接口, 不管我是在处理什么类型的handle: udp/tcp/pipe等, 都只是作为handle处理. 但是不同的这些I/O设备的I/O操作会需要更加specific的接口, eg: uv_udp_send之类的. 这些函数会使用上面给出的和eventloop交互的接口并且提供一些task-specific的callback做一些从socket里读数据啊之类的处理。
类似libuv, libev这些库实现的event loop都有多种类型的handles, 除了我们觉得理所当然的用于异步IO的handles(比如tcp/udp socket通信等), 这一类handle我们称为I/O handle, 还有prepare, check, idle类型的handle(可以看unix/loop-watcher.c里面的UV_LOOP_WATCHER_DEFINE这个工厂宏). 一个handle其实代表的是一个device(a long-lived concept).
handle上的一些I/O操作是任意时间只能同时有一个在进行的, 对于这些操作, 可以直接在handle上注册相应callback. 但是也有一些I/O操作, 可能同时有多个queue起来的该I/O操作, 这个时候就要引入另一个概念request, 不过这些request具体怎么用是不同类型的handle自己要处理的事情, 一个例子是stream handle(udp tcp pipe handle…都是stream handle的子类型)里面的write/send操作是需要一个request queue的, 而read/recv操作是不需要的.
所以在stream handle结构体里, write操作有一个write_queue来存requests, 每个request结构体里会给定每次write的callback; 而recv/read操作直接可以把read callback给在handle的结构体里。下面是stream handle 结构体uv__stream_t的定义的一些fields:

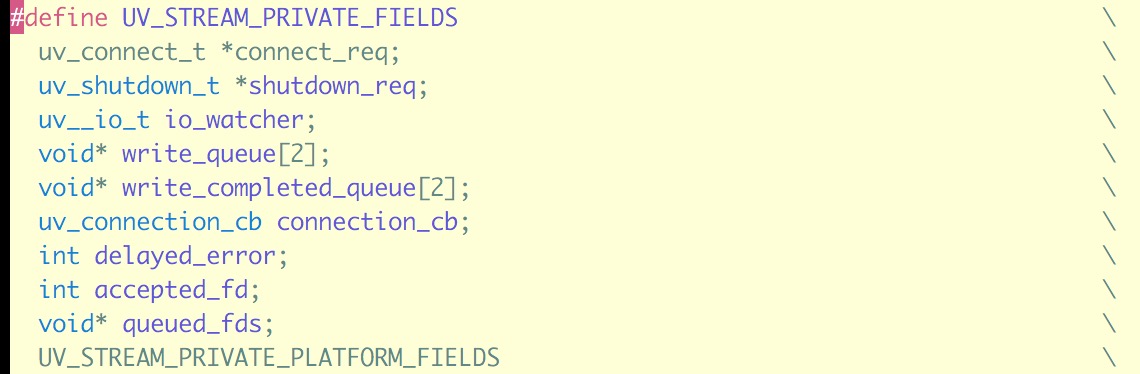
stream API的实现基本在stream.c里面十分容易理解。就不再赘述了.
总之, 所有对stream-based handle操作的API都是类似这个里面说的这样的: http://nikhilm.github.io/uvbook/filesystem.html#buffers-and-streams
epoll on Linux
这一节中将简单总结一下Linux系统上提供的epoll接口, 引出一个重要的问题。
epoll_create1: 创建一个epoll fdepoll_ctl: control interface for an epoll descriptor, 比如增加/减少监视的fd, 或者修改监视的fd的event类型epoll_wait: blocking的调用, 可以设置timeout, 如果该epoll fd监视的fd中有事件发生, 会返回一个整数代表有多少个fd有事件发生。并且把events存入一个buf里。
可以查看unix/linux-core.c:uv__io_poll看具体是怎么调用的。
既然底层用的是EPOLL, EPOLL能帮我们multiplex监听多个fd. 那我们看看EPOLL有什么不能做的, Linux上普通文件(不是pipe, socket等), 是不支持epoll操作的, 因为普通文件的access本身就不会阻塞, 没有数据就返回EOF.
但是其实很多对超大普通文件的访问也很耗时间, 其实一个很自然的想法, 就是用一个后台线程来blocking的操作普通文件, 然后当I/O操作完成了, 这个后台线程就可以告知eventloop。告知的方法当然最好和其它I/O操作告知的方法要统一, 其它I/O event出现时, epoll_wait会检测到某个fd上有事件, 所以很自然的想法就是在后台线程和前台线程之间维护一个pipe嘛, pipe的fd是可以被epoll监视的。这个确实是很直接的想法, 之前自己看到Linux上普通文件存在不能epoll的问题时, 自己想的解决方案也是这样。
libuv里对普通文件I/O的处理用的就是这个想法:
The libuv filesystem operations are different from socket operations. Socket operations use the non-blocking operations provided by the operating system. Filesystem operations use blocking functions internally, but invoke these functions in a thread pool and notify watchers registered with the event loop when application interaction is required.6. uv-book
下一节简单分析一下其实现代码。
worker thread pool
-
initalization: libuv中抽象出 async handle
uv_async_t代表需要用worker thread pool进行操作的任务. 在uv_loop_init里做了async handle的初始化. 会调用uv__async_start里创建一个pipe用于thread pool告知eventloop的epoll做完工作了, 并在io handleloop->async_io_watcher上让其监听pipe的read端, 注册callbackuv__async_io.. 这个io handleloop->async_io_watcher会用uv__io_start交给loop监听(与其它I/O操作监听方法一样)。 -
submit work: 向libuv申请一个在thread pool里执行的带callback操作的函数调用为:
uv_work_submit, 就是把一个work structuv__work_t类型的work插入一个queue里。 -
thread fetch and do the work: thread_pool.c里根据环境变量
"UV_THREADPOOL_SIZE"初始化该大小的一个thread pool (unix下就是pthread_create创建的thread). 每个thread里跑的程序很简单就是一个,不断从queue里拿任务并运行的workload. 完成任务后会调用uv_async_send, 这个函数在UNIX系统上就是写pipe的write端。 -
callback: 下面来看如果epoll从该pipe的read端得到了event, 回调顺序: 前面说到交给loop 的watcher queue的watcher是
loop->async_io_watcher, 其callback为uv__async_io, 会调用handle->async_cb, 这个callback在loop初始化时就注册为了uv__work_done.uv__work_done会调用用户用uv_work_submit提交的work struct里面的done函数。这样就完成了回调过程.
用uv_work_submit实现各种file system访问API的例子可以看unix/fs.c里面的实现。
libuv currently uses a global thread pool on which all loops can queue work on. 3 types of operations are currently run on this pool:
- Filesystem operations
- DNS functions (getaddrinfo and getnameinfo)
- User specified code via uv_queue_work()
js Promise
以node.js为例, 讲一讲Promise。 前面提到node.js原生提供的各种API都是callback-based API, 马上可以看到这种API相比同步编程的API来说更不好写出清晰简洁的代码。而Promise是除了前面提过的基于coroutine context switching对上层提供同步编程的API以外, 另一种能够让上层的编程能写出清晰简洁代码的方式。比起类似操作系统做的context switching hack, 这种方式更像利用函数式编程里对I/O result进行封装的思想, 下面来看看。
node callback
写过一点node的人都知道, 写node的时候程序员在用event-based programming, 各种函数调用都是用callback形式处理其结果。标注的格式都是第一个参数为err, 表示是否有错误发生, 后面是其他的参数。
这种callback方式有什么不好呢? 比如我要顺序做一系列顺序的涉及到I/O操作的函数调用, 写出来的代码类似于:
func1(args1, function(err, res) {
var args2 = do_some_thing2(res);
func2(args2, function(err, res) {
var args3 = do_some_thing3(res);
func3(args3, function(err, res) {
var args4 = do_some_thing4(res);
func4(args4, function(err, res) {
...
});
});
});
});
这个嵌套一两层还好, 层数多了连缩进都经常看不清。或者如果我有一个函数数组funcList = [func1, func2, ... funcN]需要按照这种链式的方法调用, 这就需要用一个recursive调用的函数, 接受一个当前indexrecursive增加index然后调用自己来实现。这样的代码写出来真的还蛮confusing的, 没有了同步编程paradigm情况时顶层代码中集中控制执行流程的这种smell good的感觉…这就是因为一个想要异步链式调用一堆函数的时候, 只有在callback中才能得到下一个callback要用的数据, 所以必须嵌套的一直把结果传递下去。(这个是不是叫做callback hell???好像是?) 当然这种写代码不好看或者不易理解/维护的问题还是可以用一些工具库比如async啥的里面提供的一些waterfall啦之类的帮助函数解决。
但是如果我还要做error handling, callback-based programming的另一个缺点也出现了, 因为我们知道这种基于callback的non-blocking函数调用, 你是不能期待这样抓住callback函数里的exception的:
try {
func(args, function(err, res) {
if (!err) {
do_some_thing_that_can_throw(res);
}
});
} catch(err) {
... do some error handling
}
这显然是callback机制决定的, 这个callback是在之后有I/O事件发生的时候才会被eventloop调用。 所以如果要处理callback函数里可能throw的exception, 只能在callback函数里处理。而且在一个链式调用中, 每个callback函数基本都需要判断err参数是不是非空。这样我就不能把exception/error handling统一在一个地方, 而是要分散到每个callback函数中。没有了central controlling并且有了很多冗余的做错误处理以及做错误传递的代码。
所以, 我需要一个抽象, 这个抽象能解决callback-based programming会导致很多很多层的嵌套, 不能在一个地方做central controlling和central exception/error handling的问题。callback-based programming不能做central controlling而是需要多层嵌套的原因, 是callback的结果(res1)需要在callback(func1)里才能传递给下一个callback(func2),那我们可以想到能不能让一个I/O函数(func1)返回一个对象(async_res1)代表一个async的操作结果, 我们把这个async的操作结果传给下一个callback(func2(async_res1)), 而不是在callbackfunc1中用调用func2(res1)。如果我们能实现这样的抽象, 我们就能把控制程序执行逻辑的代码都写在顶层block, 各个函数本身只需要返回一个对象代表async的操作结果并不需要管着去调用下一级callback。这个抽象就是Promise了, 好像这个概念已经有很长历史了, 也不是javascript发明的, 下一节将基于node.js的实现讲一讲。
其实真的对Node.js不熟, 也就用过两次。这次的项目时Promise已经是主流了, 花了半天看了一下, 感觉蛮有意思的就写点东西… 很可能有些理解不对… 可能以后再来看看检查一下hhh
Promise实现
Promise 是一个用在异步编程里的概念。感觉与Haskell里的Monad的思想类似,是一个包装了异步IO操作的结果的对象。可以把Promise看作一个箱子(box), 封装了异步IO操作在未来会得到的数据。其代表的异步操作并不一定执行完了, 很可能在后台执行。如果要查验这个Promise对象async_res1封装的异步IO操作真正得到的结果res1,也就是开箱操作,若该异步操作没有执行完就会block. 但是一般来说我们写代码的时候当然是想要等这个异步操作有结果了, 再在这个异步操作的结果res1上继续调用下一个函数func2, 这就是Promise的then操作出场的地方, then操作做的事情其实就是在这个async result async_res1上注册一个callback, 关键在于, async_res1.then操作会返回另一个async result:
var async_res2 = async_res1.then(func2);
然后这个async_res2又是thenable, 可以继续这样链下去, 并且这个链的error handling可以在最后用一个统一的catch处理:
func1()
.then(func2)
.then(func3)
.then(func4)
.catch(error_handler);
用这种方式编程就没有刚刚说的太深嵌套的问题了, 程序控制流和error-handling都是集中在顶层block执行的。把每个异步函数的逻辑和其完成后要被用来做什么的逻辑分离了, 现在要对数据做后续处理不再是传给函数一个callback让那个函数负责调用, 而是顶层代码在async resultPromise注册callback实现。那么接下来的问题就是, 我们现在有的是callback-based的一堆utility, 要怎么利用callback-based functions在语言里实现这个抽象呢。也就是说本来有一函数func1(args, callback), 接受一个callback, 自己本身并不返回值, 我要怎么样把这个函数封装成promisified_func1, 想要其不接收callback, 返回一个async result, 接下来在这个async result上可以调用then方法。这个async result我们称为一个Promise。下面先定义Promise这个类型(用javascript里的constructor pattern定义), 然后定义一个promisify函数接收一个本来接受callback的函数, 返回一个不接受callback会返回Promise的函数。具体的specification见https://promisesaplus.com/
写不动了, 随手找个链接贴上来先: https://github.com/xieranmaya/blog/issues/3
Gevent
再提一嘴之前一直用来举例子的gevent, 毕竟相对node.js和golang, 还是对Python和C比较熟, 前面说到Python里的gevent会做的几件事:
- patch I/O call: 用monkey-patch的方式把类似
socket.socket.recv这些方法patch 成non-blocking的函数, 改成在eventloop上注册事件然后交出执行权的调用。 - user space context switching: 用于协作式的交出执行权, 具体的实现在greenlet库里, 具体可以查看
greenlet.c:g_switchstack函数, 其中还调用了slp_switch是一个用不同平台的汇编语言写的进行一些神秘的栈操作的context switching函数。 - eventloop: gevent里面用的eventloop实现是在libev库里, 与libuv的实现大同小异。
gevent用于运行eventloop的greenlet称为Hub, 其它所有greenlet调用patched I/O function的时候会调用Hub.wait(watcher), 这里面的watcher.start会把waiter.switch注册为该watcher的callback, 并向loop注册该watcher, 这个waiter.switch callback就是切换回当前greenlet context的函数, 封装了greenlet提供的context switching API; 然后调用waiter.get进而调用hub.switch()切换到hub greenlet的context。即所有协程在进行需要block的I/O操作时, 都是把执行权交给hub greenlet, 再由运行eventloop的Hub greenlet在有事件的时候分配执行权给可运行的greenlet。
对这些概念我们已经很清楚了, 不过这里有个问题, gevent可以patch python的方法, 在python 代码里调用hub.switch()就可以交出执行权, 那如果要调用的用C写的extension module里有blocking I/O的libc调用怎么办? 那么就需要其它的方法把C函数也给patch掉, C写的函数已经编译到动态库(比如叫liba.so)里, patch这个函数没有patch python的函数那么简单… 不过也是能做的, 这个坑还蛮大的, 而且和平台的可执行文件格式, 动态链接的细节十分相关。以Linux为例, 大概意思就是: 如果一个程序调用了一个动态链接库里的函数func1, 流程是这样的(下面的图片中直接用libc_start_main函数作为func1的例子了):
- PC指向
func1的plt stubfunc1@plt处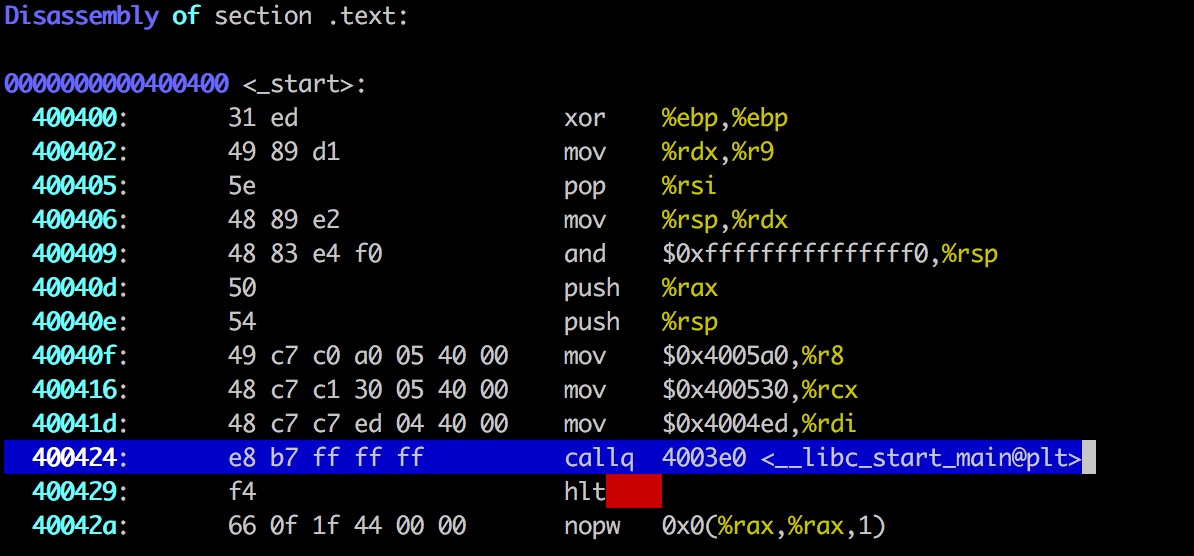
- PLT stub里的第一句指令就是跳转到GOT(
GLOBAL_OFFSET_TABLE)表的一个表项指定的地址, 这个GOT表中表项与每个可能会调用的动态链接库函数一一对应, 为该函数的入口地址。
- 如果这个函数
func1还从来没有在此程序中调用过, 其对应的GOT表项的初始地址指回func1@plt+ 0x6处(在图例里是4003e6, 注意小端字节序), 这处的指令就是push一个参数, 并调用操作系统提供的dynamic loader。下图为elf文件里记录的GOT表初始值。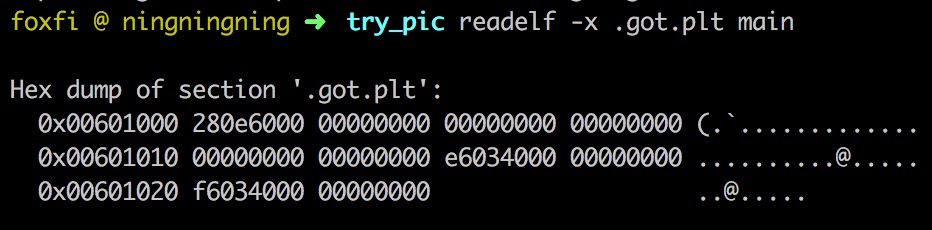
- dynamic loader发现你要调用的这个函数是在哪个动态链接库里, 把这个动态链接库里的该函数
func1的代码块通过虚拟内存映射的方法只读的映射到当前进程的shared lib内存区域。然后修改内存里的GOT表项里对应func1的表项为映射到的这个内存区域的地址。 - OK. 之后再调用
func1查GOT表就会直接跳转到shared lib内存区域func1的指令区域了。
NOTE: 为什么动态链接库的调用机制需要这个
GOT呢, 因为dynamic linker总不能在运行时修改内存中code区域, 把代码中所有调用了func1的地方都填入func1的入口地址吧, 所以加入了一层indirection layer做一次table lookup。为什么需要这个plt stub呢, 这是在做一个lazy的library loading, 很可能你的程序的某次执行路径根本没有调用func2函数, 那么func2的代码块并不需要在这次执行过程中被映射到此程序内存空间的shared lib区域, 如果当前也没有其他进程在使用func2所在的动态链接库, 很可能func2所在的动态链接库都不需要加载。所以这个lazy的library loading可以减少Physical-Virtual mem mapping, 节省这些mapping的时间, 甚至省出physical memory空间。
知道了动态链接库里函数的执行方法, 想要patch一个调用func1要怎么做呢? 很简单嘛… 在运行时把自己进程内存的GOT表里对应func1的表项写成我新定义的函数的地址就好了. 每一个需要从动态链接库里调用的函数都会在elf文件的relocation section里有一项, 如下图所示。记录了符号、符号类型和对应的GOT表项的offset。
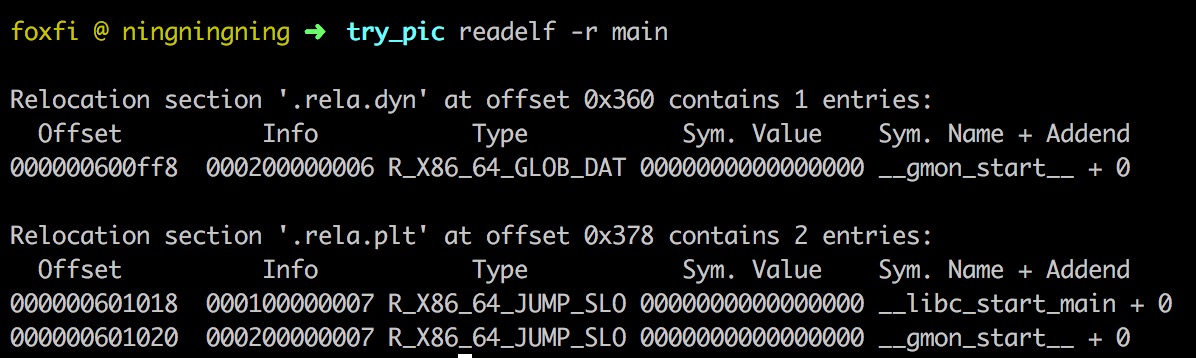
所以回到我们的目标, 我们想要运行时patch我这个程序要调用的libb_python.so这个C extension module, 这个module里调用了一个I/O函数func1函数(假设原来定义在liba.so里), 我想将func1调用patch成我自己定义的函数fake_func1. 要做的事情就是, open libb_python.so读到relocation section的信息, dlopen(dynamic linker提供的API) load libb_python.so, 在relocation section信息里找到func1, 然后往其GOT offset处(需要加上dlopen得到的该库load进来之后的base address)写入fake_func1函数的地址。当然还有不少细节…memory page权限要改(mprotect), non-PIC的非动态链接库并不是这样工作的啦之类的, 不过对于大多数PIC编译的动态链接库大致就是这个意思啦。可以看看田老师写的greenify里具体是怎么做的, 里面也有一些注释。
一些ref
- epoll实现原理: https://www.quora.com/Network-Programming-How-is-epoll-implemented
- golang 1.2 preemption实现: https://golang.org/doc/go1.2#preemption
- golang preemption设计稿: https://docs.google.com/document/d/1ETuA2IOmnaQ4j81AtTGT40Y4_Jr6_IDASEKg0t0dBR8/edit
- gevent monkey patch: http://www.gevent.org/intro.html#monkey-patching
- go scheduler https://morsmachine.dk/go-scheduler
- uv-book http://nikhilm.github.io/uvbook/ http://nikhilm.github.io/uvbook/basics.html
- 关于怎么实现user space context switching, 用汇编写的换栈指针的一些trick可以查看libco(微信后端的协程库, 没看过)或者greenlet(gevent依赖): https://github.com/Tencent/libco https://greenlet.readthedocs.io/en/latest/
